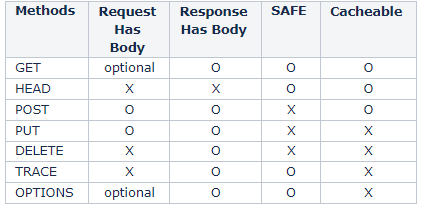
branch
기본 브랜치로부터 파생한 독립적인 공간으로, 커밋을 가리키는 포인터를 나타내며 가볍고 생성/이동/병합이 쉬움(기본 master브랜치)
- 개발 진행 중에 발생한 문제점을 해결하거나 개선하기 위해 사용
- 오픈 소스 프로젝트인 tensorflow의 브랜치(1월19일 기준 45개의 브랜치)

- 현재 작업 중인 브랜치: git branch

- 브랜치 생성: git branch "생성 브랜치 명"
- 특정 브랜치로 분기: git checkout "생성 브랜치 명"
- 이전 브랜치로 분기: git checkout -
- 브랜치 생성과 동시에 해당 브랜치로 분기: git checkout -b "생성 브랜치 명"
- 실습
- master브랜치에서 3번의 커밋, 그리고 branch_test브랜치에서 1번의 커밋한 상태

- 로그 확인

- master브랜치의 커밋로그
- 당연히 branch_test에서 변경한 파일 기록이 보이지 않음

- 새로운 issue_branch에서 test5메세지로 커밋, master브랜치에서 test6으로 커밋한 상황
- issue_branch브랜치에서 branch_test브랜치에서 변경한 코드 이력이 보이지 않음

- 전체 branch flow
- 새로운 브랜치로 코드 이력을 수정함으로써 발생할 수 있는 개발 이슈 관리

- 모든 커밋 기록 확인
git log --all --graph

또한 gitk 명령어로 브랜치와 커밋 이력을 관리할 수 있음

브랜치 병합과 conflict
새로운 브랜치를 생성하여 작업함으로써 코드 이슈를 해결 한 뒤 기준 브랜치로 이동하여 파일 내용 병합
현재 기준 브랜치: master
case) issue_branch를 master로 병합

conflit발생
→ 원인 파악을 위해 test.cpp파일 내용 확인

master브랜치 8번째 라인
→ "cout<<test6<<endl;"
issue_branch 브랜치의 8번째 라인
→ "cout<<issue_branch<<endl;"
즉, 병합을 해야하는데 각각의 브랜치의 같은 라인 번째 코드가 서로 달라서 conflict발생 → 직접 수정→ add/commit→ 병합 완료


** 병합 후 브랜치 상태
- issue_branch

- master branch

→ 브랜치의 위치만 최신 커밋으로 바꾸는 상태
전체 브랜치 상태

→ issue_branch에서 작업 후 master로 merge했기 때문에 issue_branch는 삭제해 줘야함.
git branch -d issue_branch

issue_branch만 삭제 되었을 뿐 여전히 master는 test6과 test5 커밋을 가리킴
방금 진행했던 병합은 master-issue_branch 간 병합
3 way merge
아래 3가지 정보를 이용하여 merge한다.
1) master와 branch_tset의 공통 조상 커밋(→ test3)
2) master 브랜치의 최신 커밋
3) branch_tset의 최신 커밋
아래와 같은 파일 상태에서 merge.(같은 라인에 코드가 각각 다르므로 conflict발생)

파일 직접 수정 후 merge 완료한 상태(merge후 branch_test삭제)

최종 브랜치 상태


총 비교(최초, issue_branch 작업 후, branch_test 작업 후)
→ 2개의 issue브랜치 병합, branch_test 커밋으로 master 브랜치에 병합 됐음.

tag
- 태그는 특정 시점의 소스 코드 정보를 기록
- 프로젝트 진행 중 의미 있는 시점의 커밋을 태깅한 것
*의미 있는 시점: 1차 목표 기능 개발 완료, 이슈 해결 완료, 개발 및 테스트까지 완료, 배포 시점 등등
실습 예에서는 issue_branch와 branch_test로 이슈를 관리, 해결 후 병합했기 때문에 tag가 필요 있는 시점임.
- Lightweight태그: 버전 명과 같은 태그 명만 남기는 태그
- git tag "태그 명"
- Annotated태그: 태그를 만든 사람의 이름, 메일, 태그 생성 날짜, 태그 메시지 등의 정보를 저장한 태그
- git tag -a 태그명 -m "태그 메시지"
- git을 이용한 태그 생성 시점과 규칙은 조직마다 다를 수 있으며 중요한 것은 소스 코드의 효율적 관리를 위해 일관성 있는 규칙을 정하여 준수하는 게 중요.

git show 태그 명
→ 태그 정보들이 출력됨

특정 시점 커밋 태그하기
- 태깅하고자 하는 커밋 id 확인
- git log --oneline

- 커밋id값을 인자로 사용하여 태깅하기
- git tag -a 버전명 커밋ID -m "태그메시지"
- 실습case에서는 branch_test를 병합하기 전에 병합했던 issue_branch커밋 기록을 v0.9로 생성함.

- 태그 정보확인
- git show v0.9

gitk 로 본 브랜치 상태

Git flow
아래 브랜치들을 활용하여 변경점을 관리하는 모델
- master branch
- 실제 고객에게 릴리즈되는 브랜치. 모든 변경사항은 결국 master로 최종 반영되어야 함.
- develop branch
- 실제 개발의 중심이 되는 브랜치. 기능추가/버그 수정 후 배포 가능한 수준이 되면 master에 최종 반영.
- feature branch
- 기능을 개발하기 위해 develop브랜치로부터 분기되어 사용됨. 분기 단위는 기능추가, 스프린트 주기 등이 있음. 기능 개발이 완료되거나 스프린트 주기가 종료되면 develop브랜치로 내용 merge후 브랜치 삭제.
- release branch
- 배포를 준비(검증, 이슈 수정 등)하는 브랜치. 배포 가능 상태가 되면 master브랜치로 병합하며 release브랜치에서 기능 점검 시 발견한 이슈 수정사항은 반드시 develop브랜치에 병합해야함. 배포 준비가 완료되면 최종 master로 병합하고 태깅해야함.
- hotfix branch
- 배포한 버전에서 발생한 장애 및 버그 발생 시 대응하는 브랜치. master로 부터 분기되며 이슈가 수정되면 수정사항은 master, develop브랜치에 최종 반영되어야 함.
Git flow는 고안된 하나의 모델일 뿐 git의 일반 명령어와 함께 사용할 수 있음(git flow 모델 managing을 위한 별개의 명령어x)
git flow 흐름 모델을 제거하는 코드
https://stackoverflow.com/questions/18480923/is-there-a-command-to-undo-git-flow-init

- gitflow 브랜치 초기화
- git flow init

- gitflow 기능 개발
- git flow feature start "개발할 기능명"

코드 참고 >>
- 기능 개발 완료 시?
- git flow feature finish "개발한 기능명"
- 순서: feature 브랜치→ develop브랜치로 merge→ feature브랜치 삭제→ develop브랜치로 이동
- gitflow 기능 협업 개발
- 다수의 개발자가 함께 기능 개발 시 원격 저장소에 기능 브랜치 게시후 개발
- git flow publish finish 개발할 기능명
- 원격 저장소의 feature 브랜치를 로컬로 pull
- git flow feature pull origin 개발할 기능명
- gitflow 릴리즈
- 시작: git flow release start "버전명"
- 게시: git flow release publish "버전명"
- 종료: git flow release finish "버전명"
- gitflow 긴급 이슈 대처
- hotfix 생성: git flow hotfix start "새 릴리즈 버전"
- hotfix 완료
- 순서: hotfix브랜치가 master, develop에 merge됨→ hofix브랜치 삭제됨→ develop 브랜치로 이동