저번시간 까지는 웹 크롤링을 활용하여 다양한 정보들을 추출했는데,
이번시간에는 공공데이터API를 활용하여 실시간 버스 도착정보를 얻어보겠습니다.
저는 제가 주로 이용하는 한 버스 정류소의 실시간 버스 도착 정보를 얻기 위해 사용했습니다.
마을 버스 한 대만 통행하는 일부 정류소는 버스 도착 정보가 잘 조회되지 않는 것 같아서 최소 4대가 통행하는 정류소를 선정했습니다.
*누구나 겪을 수 있는 시행착오에 대한 부분도 포함되어 있기 때문에 한번 쭉 읽고나서 따라하실 것을 권장합니다.
공공데이터 포털에 접속하여 '서울특별시_버스도착정보조회 서비스'를 신청합니다.
공공데이터 포털
국가에서 보유하고 있는 다양한 데이터를『공공데이터의 제공 및 이용 활성화에 관한 법률(제11956호)』에 따라 개방하여 국민들이 보다 쉽고 용이하게 공유•활용할 수 있도록 공공데이터(Datase
www.data.go.kr
서비스 신청 후 API키가 발급되는데, 서비스를 바로 이용할 수 있는 것은 아니고 어느정도 시간이 소요된 후 이용할 수 있습니다.
서비스 종류에 따라 짧게는 1~2시간에서 길게는 하루 넘게 걸리는 서비스도 있다고합니다.
서비스가 아직 서버에서 승인되지 않아서 발생하는 오류와 잘못된 데이터를 기입해서 발생되는 오류는 다르기 때문에 이를 헷갈리시면 안됩니다.
간혹, 서비스는 정상적으로이용할 수 있는데 본인이 잘못된 데이터를 입력하여 발생한 오류를 API키의 발급이 느려져서 발생하는 오류라고 오해하시는 분들이 계셨습니다.
제가 포스팅 한 글을 참고하시면 좋을 것 같습니다.
https://jow1025.tistory.com/318
공공데이터 api 신청 후 서비스 호출 에러
실시간 도착 버스 정보 조회 API를 신청하고나서 짧게는 1시간 길게는 2일 정도 사용허가를 해준다 그랬는데 신청하고 20분후에 아래 처럼 승인이 나 있었습니다. 되게 빨리 됐다 싶어서 바로 사
jow1025.tistory.com
이제 발급받은 키를 활용하여 openAPI를 활용해보겠습니다.

2,4번은 구현할 서비스에서 딱히 참고할 만 한 게 없고 3번 서비스가 우리가 구현할 목적에 적합하므로 이를 이용합니다.
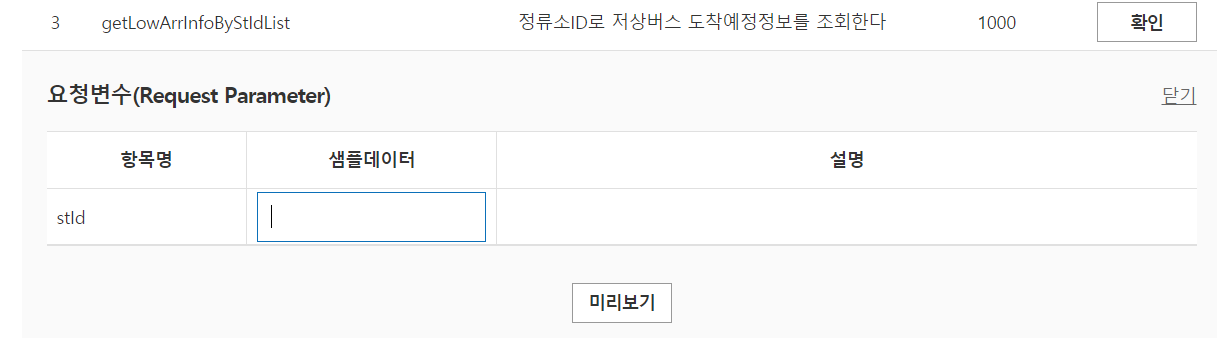
테스트를 위해 아래 샘플데이터에 자기가 조회할 버스정류장의 ID를 적어주면됩니다. stID는 정류소ID를 의미합니다.
정류소 ID를 알아내기위해 버스정보 사이트에서 개발자 도구로 어떤 정보를 얻을 수 있는지 확인해봅니다.
서울버스정보 조회 사이트에 접속하고 조회할 정류소 이름을 검색합니다.
https://bus.go.kr/searchResult6.jsp
버스도착정보
bus.go.kr
조회하면 오른쪽 지도에 아래처럼 버스 아이콘이 뜨는데,

개발자도구(F12)를 킨 다음 이 아이콘을 클릭하면 개발자도구 상단 Network탭에 아래 3가지 .jsp 목록이 나타납니다.
getStationByUid.jsp를 클릭해보면,

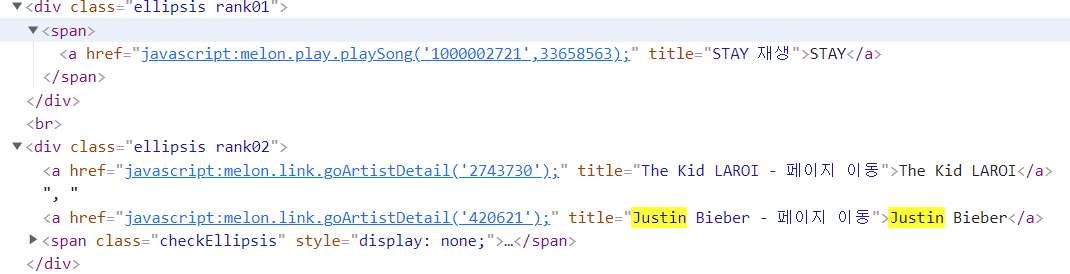
아래와 같이 특정 버스(6630버스)의 정보를 알 수 있는데, (정류소 고유번호, 노선 이름, 노선ID, 등)

우리가 공공데이터 API를 사용하여 얻고자 하는 데이터는 아래 목록 중 rtid(노선번호,=버스이름),arrmsg1,arrmsg2(첫번째, 두번째 버스 도착 예정 시간)입니다.
아까 위에서 API활용 3번 째 서비스를 이용하려면 정류소 ID가 필요하다고 했는데 그것까진 출력되지 않는 것 같습니다.
++++++++++
다른 사이트를 참고해볼까요?
++++++++++++
아래 사이트에서 조회하니깐 버스정류장 id를 포함한 더 자세한 정보들까지 출력되는 것 같으니 위 사이트보다 아래 사이트를 이용하시는 것을 강추합니다.
https://topis.seoul.go.kr/map/openBusMap.do
버스정보 조회 | 서울시 교통정보 시스템 - TOPIS
topis.seoul.go.kr
버스 id까지 다 나오는데, 이를 이용하면됩니다.

------------------------------------------------------------------------------------------------
두번째 버스정보사이트에서는 정류소 ID까지 출력되므로 정류소 id정보를 얻기위한 아래 과정은 생략해도됩니다.
저는 첫번째 버스정보사이트에서 정류소 ID를 못찾았다는 것을 가정하고 진행하겠습니다.
------------------------------------------------------------------------------------------------
그럼 어떻게 정류소 ID를 얻을까?
다시, 아까 위에서 본 서비스 목록 중 1번을 펼쳐보면 노선번호(busRouteID)를 적어서 기능을 테스트해 볼 수 있음을 확인할 수 있습니다.

위에서 개발자 도구로 살펴본 정류소 정보를 보면 6630번 버스의 Id가 100100307임을 알 수 있었는데 100100307을 입력하고 미리보기 버튼을 클릭합니다.
그러면 아래처럼 되게 많은 데이터들이 출력됩니다.

서비스 설명에 나와있듯 "경유노선 정류소 도착예정 정보" 가 출력됩니다. 설명이 약간 헷갈릴 수 있는데,
방금 입력한 id값 100100307(6630번버스)가 경유하는 모든 버스 정류소와 그 정류소들에 도착할 6630번 버스의 정보가 출력되는 것입니다.
마이페이지에서 openAPI상세 페이지를 클릭하여 변수들을 살펴보면,

우리가 알아내야할 정류소ID가 stID라는 변수명으로 매칭되어있고, 아까 개발자 도구로 살펴본 버스정보에 나온 변수와똑같거나 비슷한 이름의 변수들이 보입니다.
이제 위의 XML파일에서 ctrl+f로 정류소이름을 검색한 뒤 해당 정류소의 stid를 찾아냅니다.

이 stid를 3번 서비스에 입력하고 미리보기 버튼을 누르면

보여지는 xml데이터가 바로 버스 정류장에 도착하는 버스 정보가 되는 것입니다.
순서를 정리하자면,
1. 버스정보사이트에서 개발자 도구로 본인이 검색할 정류소를 경유하는 버스의 id 알아내기
2. open API 1번 서비스에 1번에서 알아낸 버스 id를 입력 후 경유하는 모든 정류소 목록 중 본인이 검색하고싶은 버스 정류소 ID를 알아내기
* 2-1) 아래 사이트에서 개발자도구로 2번 내용을 쉽게 확인가능
https://topis.seoul.go.kr/map/openBusMap.do
버스정보 조회 | 서울시 교통정보 시스템 - TOPIS
topis.seoul.go.kr
3. 이 id를 이용, open API 3번에 입력하여 정류소를 경유하는 모든 버스의 도착 예정시간 얻기
이 순서대로 진행하여 3번 서비스 xml파일에서 해당 정류소를 경유하는 모든 버스 리스트를 조회할 수 있고 도착 정보를 확인할 수 있습니다.

열린 xml파일에서 각 버스의 arrmsg1 변수(첫번 째 도착예정시간)가 잘 출력되시나요?
저는 일부 버스 상태가 "출발대기"밖에 안뜨고 가끔 도착예정 정보가 뜨는데 서비스가 안정적이진 않은 것 같습니다.
다른분들은 도착예정시간이 잘 뜨는지 궁금합니다.
3번 서비스 설명에 적힌 "저상버스"의 의미가 정말 사전적인 의미의 "低床버스, 영어: low-floor bus)는 바닥이 낮고 출입구에 계단이 없는 버스"(출처: 위키백과) 여서 일반 버스의 경우 조회가 안되는건지, 아니면 서비스 자체가 불안정해서 그런건지는 잘 모르겠습니다.
이제 이 내용을 파이썬 코드에서 필요한 부분(버스이름, 도착예정시간)만 추출할 수 있도록 코딩해야합니다.
일단, 방금 확인한 xml파일의 주소이름을 보면,
http://ws.bus.go.kr/api/rest/arrive/getLowArrInfoByStId?serviceKey=api키&stId=정류장id 형태로 되어있습니다.
대충 api키와 정류장id만 인자로 넣어주면 서비스 받을 수 있다는 것을 예상할 수 있는데, 실제로 확인해봅니다.
서비스 페이지에서 활용가이드 docs를 열어봅니다.

초반부분을 보시면 서비스 유형은 REST, 데이터 포맷은 XML, 교환 유형은 Request-Response라고 나옵니다.


페이지를 내리다보면 우리가 사용할 기능의 사용 방법이 잘 나와있습니다.
api키와 정류소id만 인자로 넣어주면 서비스를 이용할 수 있음을 확인할 수 있습니다. 좀 더 내려보면 결과 예시 창이 나오는데, 우리가 아까 open한 xml파일처럼 출력된다고 설명되어있는 것입니다.

이제 코드를 작성해보겠습니다.
기본적인 챗봇 부분은 아래와 같이 설정했습니다.
|
1
2
3
4
|
elif(user_text=="버스"):
bus_info=bus_crawling()
bot.send_message(chat_id=id,text=bus_info)
bot.sendMessage(chat_id=id,text=info_message)
|
cs |
이제 구현한 함수를 보겠습니다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
def bus_crawling():
serviceKey='api키'
# 정류소 id
#stationId="115000302"
stationId="115000116"
#버스 ID
url="http://ws.bus.go.kr/api/rest/arrive/getLowArrInfoByStId?serviceKey={}&stId={}".format(serviceKey,stationId)
#get으로 요청함
response=requests.get(url).content
#xml파일을 dict로 파싱하여 사용
dict=xmltodict.parse(response)
#원하는 데이터가 ServiceResult 내부 msgBody 내부 itemList내부에 있음
#다시 dict로 받은 값을 Json로 변환
jsonString=json.dumps(dict['ServiceResult']['msgBody']['itemList'],ensure_ascii=False)
#json을 형태로 받은 데이터를 Python의 객체로 변환 (dict)
jsonObj=json.loads(jsonString)
msg=''
for i in range(len(jsonObj)):
msg+='{}\n 첫번째: {}\n 두번째: {}\n'.format(jsonObj[i]['rtNm'],jsonObj[i]['arrmsg1'],jsonObj[i]['arrmsg2'])
return msg
|
cs |
2행~9행은 사이트 이름 설정이고 11행에서 get형식으로 url을 받아옵니다.
13행은 xml을 dict형태로 파싱 해주는 코드인데
dict=xmltodict.parse(response)
이를 사용하기 위해 아래 명령어로 패키지를 설치해주고,
pip install xmltodict
맨 상단에 import json,xmltodict를 추가해줍니다.
아까 오픈한 xml파일을 보면, 구성이 아래와 같이 되어있었습니다.
ServiceResult 내부 msgBody내부 itemList 내부에 데이터가 쌓여있는데, 이 구조를 그대로 이용합니다.

17행 코드를 통해 dict를 json으로 덤프(변환)합니다.
jsonString=json.dumps(dict['ServiceResult']['msgBody']['itemList'],ensure_ascii=False)
19행에서 이 json형식을 다시 파이썬 객체(dict)로 로드함으로써 우리는 이제 버스이름, 도착예정시간을 쉽게 얻어올 수 있습니다.
jsonObj=json.loads(jsonString)
결과적으로 xml로 되어있는 url페이지를 dict로 파싱하겠다고 선언한 후 우리가 추출할 부분만 다시 json으로 변환한 뒤 이를 다시 dict으로 변환함으로써 배열인덱스 형태로 데이터를 얻어오는 것입니다.
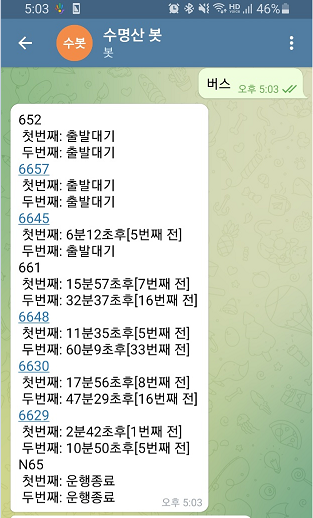
실행결과는 앞서 살펴본 xml파일의 rtNM과 각 버스의 arrmsg1, arrmsg2가 그대로 똑같이 잘 전달됨을 확인할 수 있습니다. N65는 실제 운행이 종료된 버스가 맞는데, 652,6657버스는 xml파일에서도 그렇고 출발대기로만 뜨는게 이상하긴하지만 나머지 데이터는 잘 출력되었습니다.
'웹 크롤링&API' 카테고리의 다른 글
| 텔레그램 챗봇 만들기 5단계) 실시간 동네 날씨 얻어오기 (1) | 2021.09.09 |
|---|---|
| 텔레그램 챗봇 만들기 4단계) 멜론 차트 1~10위 곡 정보 얻기 (0) | 2021.09.09 |
| 텔레그램 챗봇 만들기 3단계) 네이버 영화 순위/링크/프리뷰 받아오기 (0) | 2021.09.09 |
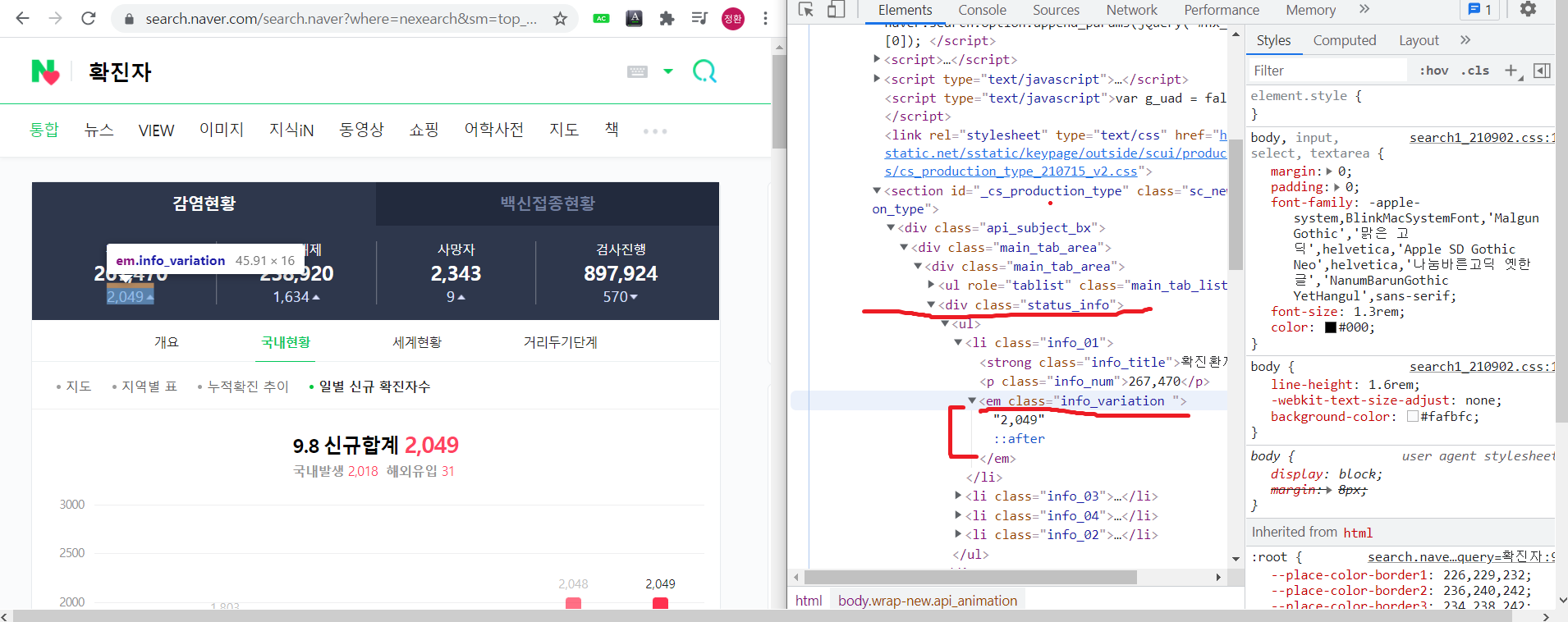
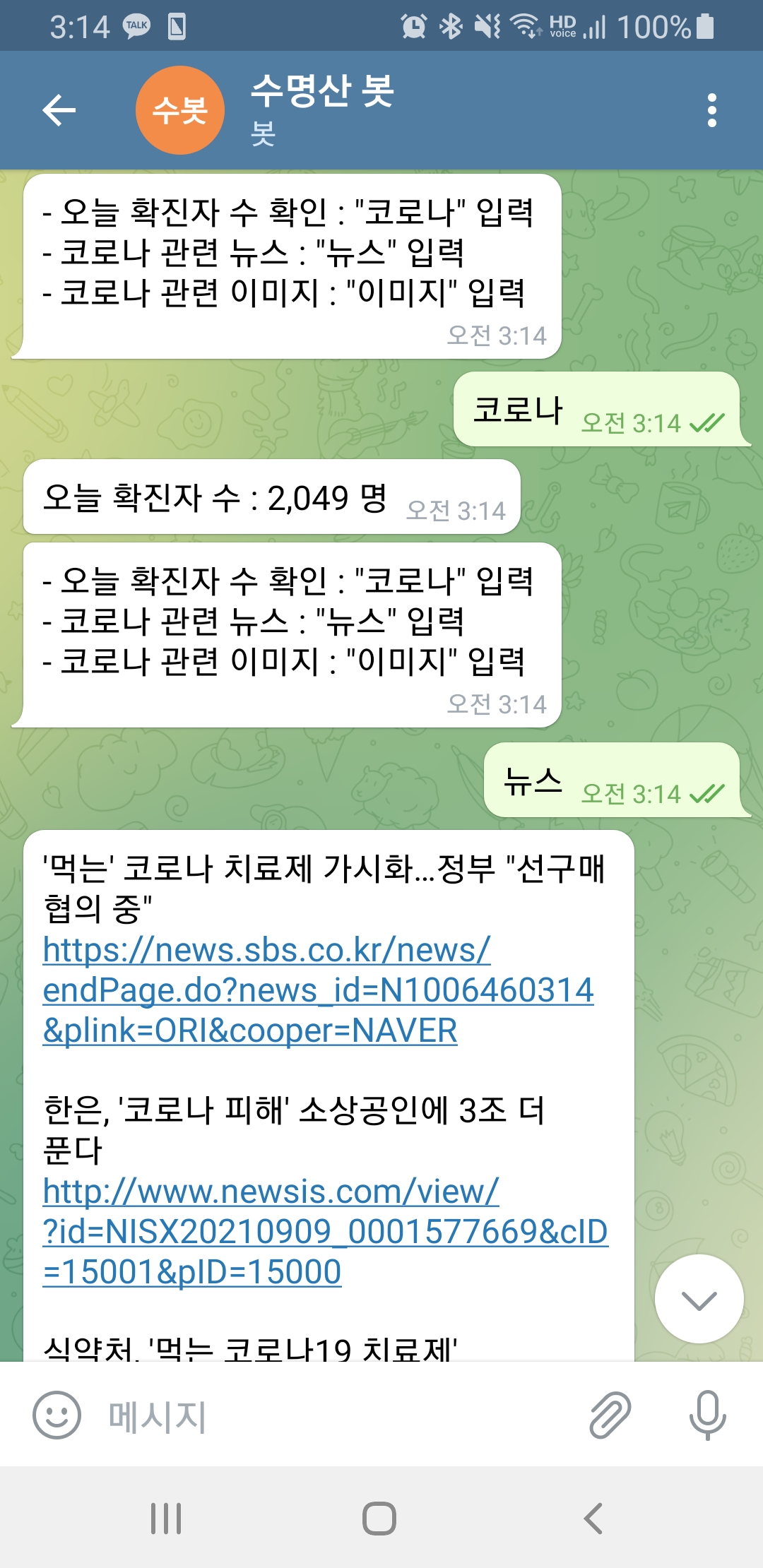
| 텔레그램 챗봇 만들기 2단계) 코로나 관련 정보 얻기 (0) | 2021.09.09 |
| 공공데이터 api 신청 후 서비스 호출 에러 (0) | 2021.09.09 |