이번시간부터 본격적으로 본인이 원하는 기능을 서비스받을 수 있는 챗봇을 구현해보겠습니다.
첫 시간이고 앞으로 많은 단계를 거쳐 웹 정보를 크롤링 할 것이므로 패키지들 부터 다 설치해주겠습니다.
저는 vscode에서 python으로 코딩하였습니다. 터미널에서 아래 명령어로 모든 패키지를 설치합니다.
pip install python-telegram-bot
pip install telegram
pip install selenium
pip install beautifulsoup4
pip install requests
Selenium은 webdriver라는 것을 통해 디바이스에 설치된 브라우저들을 제어할 수 있습니다.
주로 chrome을 많이 사용하므로 chromedriver를 설치합니다.
https://sites.google.com/a/chromium.org/chromedriver/downloads
Downloads - ChromeDriver - WebDriver for Chrome
WebDriver for Chrome
sites.google.com
주의 해야 할 것은 설치할 크롬 드라이버 버전과 자신의 크롬 버전이 일치해야한다는 것입니다.
버전이 서로 다르면 크롤링이 되지 않습니다.
자신의 크롬 버전 확인: 크롬실행-> 우상단 점3개 아이콘 클릭-> 도움말-> chrome 정보 클릭 하여 확인
설치, 압축 해제 해줍니다. 나중에 이 드라이버를 불러봐야 하기 때문에 저장 위치(경로)를 잘 기억해 둡니다.
=================================================
여기까지가 앞으로 몇단계에 걸쳐 진행할 실습을 위한 사전작업 단계입니다.
이제 실습 진행해보겠습니다.
이번시간에 웹의 정보를 크롤링하여 정보를 수집하고, 얻는 정보는 다음과 같습니다.
<웹: 네이버>
1. 코로나 일일 확진자 수
2. 코로나 관련 최근 10개의 이미지
3. 코로나 관련 최근 3개 기사 타이틀, 링크
모두 네이버에 검색한 내용을 크롤링하여 정보를 수집하였습니다.
네이버에 "확진자"를 검색 하면 아래 창이 나타나고, 개발자도구(F12)를 눌러서 확진자 수 데이터를 확인합니다.
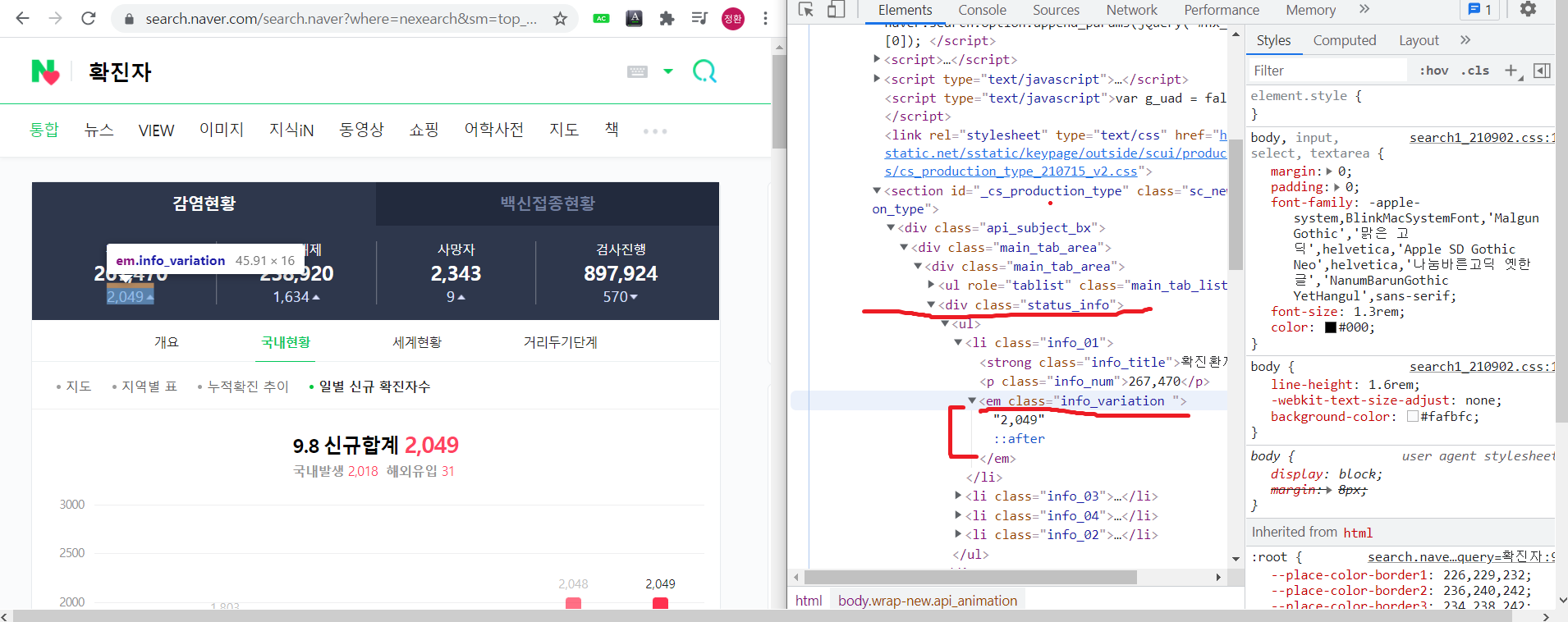
status_info 영역 내 클래스 안에 em(글꼴 강조) 클래스 안에 2049데이터가 있습니다.
이 2049 데이터를 나중에 select함수 내부에 '2049데이터 위치' 를 넣어서 그 부분만 정보를 추출할 수 있습니다.
div.status_info 안에 em 클래스안에 2049가 있네요.
이런식으로 하나씩 정보를 크롤링하여 원하는 정보만 추출할 수 있습니다.
크롤링 방법을 다루는 실습은 아니므로 구체적인 설명은 생략하겠습니다.
함수 사용은 거의 동일하고 필요한 부분은 주석으로 대체했습니다.
이제 전체 코드를 확인하겠습니다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
|
import telegram
import requests
from telegram.ext import Updater
from telegram.ext import MessageHandler, Filters
from bs4 import BeautifulSoup
from selenium import webdriver
import urllib.request as req
import os
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
API_key='knI%2FsEhuhoIf37FOmsc8uCq6qdcCXaJU9%2BKHEwgtLzMWGJ7A7LtC3w3Z3JvKzcE4cSrxn6reCcJi2FzIcKvKAQ%3D%3D'
options = webdriver.ChromeOptions()
#크롬창을 키지 않고 연결
options.add_argument('headless')
#사이즈
options.add_argument('window-size=1920x1080')
#GPU설정 X
options.add_argument("disable-gpu")
# 혹은 options.add_argument("--disable-gpu")
driver = webdriver.Chrome("./chromedriver.exe", options = options)
#확진자 검색 후 f12로 코로나 확진자 수 정보 컴포넌트 위치 파악 후 크롤링
def covid_num_crawling():
code = req.urlopen("https://search.naver.com/search.naver?where=nexearch&sm=top_hty&fbm=0&ie=utf8&query=%ED%99%95%EC%A7%84%EC%9E%90")
#html 방식으로 파싱
soup = BeautifulSoup(code, "html.parser")
#정보 get
info_num = soup.select("div.status_info em")
result = info_num[0].string #=> 확진자
return result
def covid_news_crawling():
code = req.urlopen("https://search.naver.com/search.naver?where=news&sm=tab_jum&query=%EC%BD%94%EB%A1%9C%EB%82%98")
soup = BeautifulSoup(code, "html.parser")
title_list = soup.select("a.news_tit")
output_result = ""
for i in title_list:
title = i.text
news_url = i.attrs["href"]
output_result += title + "\n" + news_url + "\n\n"
if title_list.index(i) == 2:
break
return output_result
def covid_image_crawling(image_num=5):
if not os.path.exists("./코로나이미지"):
os.mkdir("./코로나이미지")
browser = webdriver.Chrome("./chromedriver")
browser.implicitly_wait(3)
wait = WebDriverWait(browser, 10)
browser.get("https://search.naver.com/search.naver?where=image§ion=image&query=%EC%BD%94%EB%A1%9C%EB%82%98&res_fr=0&res_to=0&sm=tab_opt&color=&ccl=0&nso=so%3Ar%2Cp%3A1d%2Ca%3Aall&datetype=1&startdate=&enddate=&gif=0&optStr=d&nq=&dq=&rq=&tq=")
wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, "div.photo_group._listGrid div.thumb img")))
img = browser.find_elements_by_css_selector("div.photo_group._listGrid div.thumb img")
for i in img:
img_url = i.get_attribute("src")
req.urlretrieve(img_url, "./코로나이미지/{}.png".format(img.index(i)))
if img.index(i) == image_num-1:
break
browser.close()
#토큰 넘버
token = "토큰"
id = "id값"
bot = telegram.Bot(token)
info_message = '''- 오늘 확진자 수 확인 : "코로나" 입력
- 코로나 관련 뉴스 : "뉴스" 입력
- 코로나 관련 이미지 : "이미지" 입력 '''
bot.sendMessage(chat_id=id, text=info_message)
updater = Updater(token=token, use_context=True)
dispatcher = updater.dispatcher
updater.start_polling()
### 챗봇 답장
def handler(update, context):
user_text = update.message.text # 사용자가 보낸 메세지를 user_text 변수에 저장
# 오늘 확진자 수 답장
if (user_text == "코로나"):
covid_num = covid_num_crawling()
bot.send_message(chat_id=id, text="오늘 확진자 수 : {} 명".format(covid_num))
bot.sendMessage(chat_id=id, text=info_message)
# 코로나 관련 뉴스 답장
elif (user_text == "뉴스"):
covid_news = covid_news_crawling()
bot.send_message(chat_id=id, text=covid_news)
bot.sendMessage(chat_id=id, text=info_message)
# 코로나 관련 이미지 답장
elif (user_text == "이미지"):
bot.send_message(chat_id=id, text="최신 이미지 크롤링 중...")
covid_image_crawling(image_num=10)
# 이미지 한장만 보내기
# bot.send_photo(chat_id=id, photo=open("./코로나이미지/0.png", 'rb'))
# 이미지 여러장 묶어서 보내기
photo_list = []
for i in range(len(os.walk("./코로나이미지").__next__()[2])): # 이미지 파일 개수만큼 for문 돌리기
photo_list.append(telegram.InputMediaPhoto(open("./코로나이미지/{}.png".format(i), "rb")))
bot.sendMediaGroup(chat_id=id, media=photo_list)
bot.sendMessage(chat_id=id, text=info_message)
echo_handler = MessageHandler(Filters.text, handler)
dispatcher.add_handler(echo_handler)
|
cs |
결과 화면입니다.
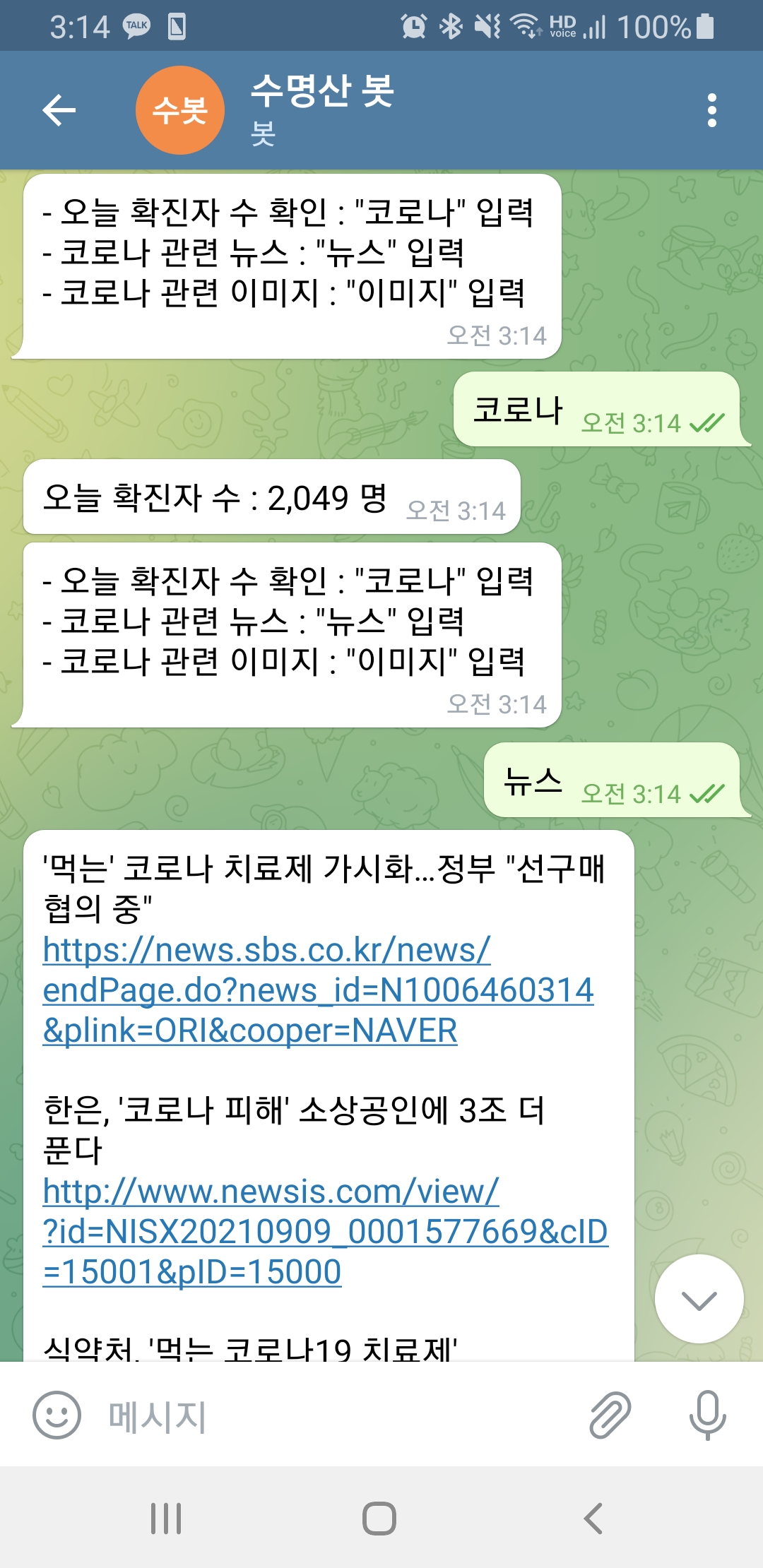
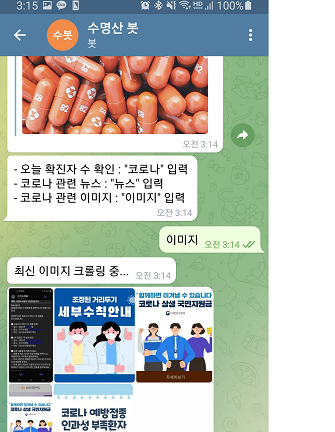
'웹 크롤링&API' 카테고리의 다른 글
| 텔레그램 챗봇 만들기 5단계) 실시간 동네 날씨 얻어오기 (1) | 2021.09.09 |
|---|---|
| 텔레그램 챗봇 만들기 4단계) 멜론 차트 1~10위 곡 정보 얻기 (0) | 2021.09.09 |
| 텔레그램 챗봇 만들기 3단계) 네이버 영화 순위/링크/프리뷰 받아오기 (0) | 2021.09.09 |
| 공공데이터 api 신청 후 서비스 호출 에러 (0) | 2021.09.09 |
| 텔레그램 챗봇 만들기 1단계) 텔레그램 설치 및 전송-응답 (2) | 2021.09.08 |